
内核环境搭建和基础知识
拖了半年的内核学习终于开始了
环境搭建
参考文章:
kernel简介
本质上来说也是个程序,就管理整个操作系统的程序,管理用户软件发出的数据 I/O 要求,将这些要求转义为指令,交给 CPU 和计算机中的其他组件处理
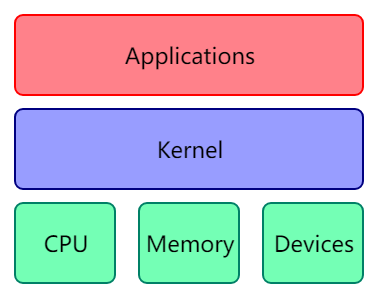
kernel 最主要的功能有两点:
- 控制并与硬件进行交互
- 提供 application 能运行的环境
包括 I/O,权限控制,系统调用,进程管理,内存管理等多项功能都可以归结到上边两点中。详细的后面再继续学习
需要注意的是,kernel 的 crash 通常会引起重启
自己编译内核:
- 安装所需要的依赖
sudo apt-get update
sudo apt-get install git fakeroot build-essential ncurses-dev xz-utils libssl-dev bc
- 下载kernel源码,这里我下载的是4.4.72版本
- 解压源码,然后在源码目录:
make menuconfig
进入kernel hacking
勾选以下项目
Kernel debugging
Compile-time checks and compiler options —> Compile the kernel with debug info和Compile the kernel with frame pointers
KGDB
然后保存退出
但基本上都默认保存了,所以检查一下然后退出就好了
- 生成kernel binary :
make bzImage
等一段时间就会出现如下信息,就意味着编译成功,然后从/arch/x86/boot/拿到bzImage,从源码根目录拿到vmlinux
Setup is 17436 bytes (padded to 17920 bytes).
System is 6797 kB
CRC c4c988d7
Kernel: arch/x86/boot/bzImage is ready (#1)
☁ linux-4.4.72 file vmlinux
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, BuildID[sha1]=d1f415bda5dcb18a110c0c741a0b4d69ebcee3a7, not stripped
☁ linux-4.4.72 cd arch/x86/boot
☁ boot file bzImage
bzImage: Linux kernel x86 boot executable bzImage, version 4.4.72 (hacker_mao@hacker-virtual-machine) #1 SMP Sat Jan 5 19:, RO-rootFS, swap_dev 0x6, Normal VGA
ps:
- bzImage是vmlinuz经过gzip压缩后的文件,适用于大内核
- vmlinux是未压缩的内核
- vmlinuz是vmlinux的压缩文件。
- vmlinux 是ELF文件,即编译出来的最原始的文件。
- vmlinuz应该是由ELF文件vmlinux经过OBJCOPY后,并经过压缩后的文件
- zImage是vmlinuz经过gzip压缩后的文件,适用于小内核
几种linux内核文件的区别: 参考:
- 几种linux内核文件的区别(vmlinux、zImage、bzImage、uImage、vmlinuz、initrd )
- Linux kernel 笔记 (8) ——vmlinux,vmlinuz,zImage,bzImage
1、vmlinux 编译出来的最原始的内核文件,未压缩。 2、zImage 是vmlinux经过gzip压缩后的文件。 3、bzImage bz表示“big zImage”,不是用bzip2压缩的。两者的不同之处在于,zImage解压缩内核到低端内存(第一个640K),bzImage解压缩内核到高端内存(1M以上)。如果内核比较小,那么采用zImage或bzImage都行,如果比较大应该用bzImage。 4、uImage U-boot专用的映像文件,它是在zImage之前加上一个长度为0x40的tag。 5、vmlinuz 是bzImage/zImage文件的拷贝或指向bzImage/zImage的链接。 6、initrd 是“initial ramdisk”的简写。一般被用来临时的引导硬件到实际内核vmlinuz能够接管并继续引导的状态。
another explaintation :
vmlinux: 一个非压缩的,静态链接的,可执行的,不能bootable的Linux kernel文件。是用来生成vmlinuz的中间步骤。
vmlinuz: 一个压缩的,能bootable的Linux kernel文件。vmlinuz是Linux kernel文件的历史名字,它实际上就是zImage或bzImage:
$ file vmlinuz-4.0.4-301.fc22.x86_64
vmlinuz-4.0.4-301.fc22.x86_64: Linux kernel x86 boot executable bzImage, version 4.0.4-301.fc22.x86_64 (mockbuild@bkernel02.phx2.fedoraproject.o, RO-rootFS, swap_dev 0x5, Normal VGA
zImage: 仅适用于640k内存的Linux kernel文件。
bzImage: Big zImage,适用于更大内存的Linux kernel文件。
总结一下,启动现代Linux系统时,实际运行的即为bzImage kernel文件。
下载内核镜像:
利用apt直接下载内核文件及源码
- 下载源码
- 先按照版本号搜索,例如4.15.0-22版本的
apt search linux-headers-4.15.0-22-
- 然后安装
sudo apt install linux-headers-4.15.0-22 linux-headers-4.15.0-22-generic
- 安装成功后就会在/usr/src目录下有源码了,4.4.0-21是本机的
☁ boot cd /usr/src
☁ src ls
linux-headers-4.15.0-22 linux-headers-4.15.0-22-generic linux-headers-4.4.0-21 linux-headers-4.4.0-21-generic
- 下载内核文件
- 同样先搜索各个版本的内核
sudo apt search linux-image-
- 然后再下载自己所需要版本的内核
apt download xxxx
- 下载下来是deb,我们解压之后在/data/boot文件夹下可以找到我们所需的内核镜像文件vmlinuz-4.15.0-22-generic,一般名字都是vmlinuz开头的
编译busybox
用来生成简易的文件镜像
busybox简介 BusyBox是一个遵循GPL协议、以自由软件形式发行的应用程序。Busybox在单一的可执行文件中提供了精简的Unix工具集,可运行于多款POSIX环境的操作系统,例如Linux(包括Android[6])、Hurd[7]、FreeBSD[8][9]等等。由于BusyBox可执行文件的文件大小比较小、并通常使用Linux内核,这使得它非常适合使用于嵌入式系统。作者将BusyBox称为“嵌入式Linux的瑞士军刀”。[10] —摘自维基百科
busybox是Linux上的一个应用程序 它整合了许多Linux上常用的工具和命令 IBM的一篇关于busybox的文章 文章地址,写的很详细。
busyboxz主要有这些功能
- busybox是Linux上的一个应用程序
- 它整合了许多Linux上常用的工具和命令
由于启动内核还需要一个简单的文件系统和一些命令,而busybox就是用来完成生成简单文件系统的
-
这里直接下载解压后进入目录,这里给出一个busybox-1.30.0的下载链接
-
输入:
make menuconfig
同样的会进入图形界面,在Settings中勾选Build static binary (no shared libs),然后save就可以了
-
编译,执行
make install,根目录下就会生成一个_install 文件夹,就是我们编译的结果了。 -
进入该文件夹_install,进行配置
cd _install
mkdir proc
mkdir sys
touch init
chmod +x init
- 编辑init文件,用于内核初始化
#!/bin/sh echo "{==DBG==} INIT SCRIPT" mkdir /tmp mount -t proc none /proc mount -t sysfs none /sys mount -t debugfs none /sys/kernel/debug mount -t tmpfs none /tmp #mount指令 挂载某个分区到某个文件,这样就将分区与文件建立联系从而访问文件时就可以访问分区。 # insmod /xxx.ko # 加载模块 mdev -s # We need this to find /dev/sda later echo -e "{==DBG==} Boot took $(cut -d' ' -f1 /proc/uptime) seconds" setsid /bin/cttyhack setuidgid 1000 /bin/sh #normal user # exec /bin/sh #root
这里提及几个常见的指令
insmod: 指定模块加载到内核中
rmmod: 从内核中卸载指定模块
lsmod: 列出已经加载的模块
接着在busybox的_install目录下输入下面的命令打包文件系统
find . | cpio -o --format=newc > ./rootfs.img
运行内核
安装qemu等相关库
sudo apt-get install libncurses5-dev
sudo apt-get install git libglib2.0-dev libfdt-dev libpixman-1-dev zlib1g-dev
sudo apt-get install qemu qemu-system
测试输入 qem+tab
如果有很多补全回显,则说明安装成功
ps:最好选个速度快的源镜像,不然真的等很久
qemu 是一款由 Fabrice Bellard 等人编写的可以执行硬件虚拟化的开源托管虚拟机,具有运行速度快(配合 kvm),跨平台等优点。
qemu 通过动态的二进制转化模拟 CPU,并且提供一组设备模型,使其能够运行多种未修改的客户机OS。
在 CTF 比赛中,qemu 多用于启动异架构的程序(mips, arm 等)、kernel 及 bootloader 等二进制程序,有时也会作为要 pwn 掉的程序出现。
运行模式
qemu 有多种运行模式,常用的有 User-mode emulation 和 System emulation 两种。
- User-mode emulation
用户模式,在这个模式下,qemu 可以运行单个其他指令集的 linux 或者 macOS/darwin 程序,允许了为一种架构编译的程序在另外一种架构上面运行。
- System emulation
系统模式,在这个模式下,qemu 将模拟一个完整的计算机系统,包括外围设备。
可以写一个shell脚本boot.sh,启动qemu,运行内核
#!/bin/sh
qemu-system-x86_64 \
-m 64M \
-kernel ./bzImage \
-initrd ./rootfs.img \
-append "root=/dev/ram rw oops=panic panic=1 kalsr" \
-netdev user,id=t0, -device e1000,netdev=t0,id=nic0 \
-monitor /dev/null \
-smp cores=2,threads=1 \
-cpu kvm64,+smep \
#-S 启动gdb调试
#-gdb tcp:1234 等待gdb调试
这里解释一下命令中的参数意义
-m是指定RAM大小(默认384)
-kernel 是指定的内核镜像,这里是我们编译的镜像路径,也可以是下载好的镜像,如./vmlinuz-4.15.0-22-generic
-initrd 设置刚刚利用 busybox 创建的 rootfs.img ,作为内核启动的文件系统
-append 附加选项,指定no kaslr可以关闭随机偏移
--nographic和console=ttyS0一起使用,启动的界面就变成当前终端
-s 相当于-gdb tcp::1234的简写,可以直接通过主机的gdb远程连接
-monitor配置用户模式的网络#将监视器重定向到主机设备/dev/null
-smp 用于声明所有可能用到的cpus, i.e. sockets cores threads = maxcpus.
-cpu 设置CPU的安全选项
S -s
開機的時候就停下來,並開啟port 1234讓gdb從遠端連入除錯
-nographic
懶得跳一個視窗,直接terminal當console使用
eg: 以 babydriver 的启动程序为例:
qemu-system-x86_64 -initrd rootfs.cpio -kernel bzImage -append 'console=ttyS0 root=/dev/ram oops=panic panic=1' -enable-kvm -monitor /dev/null -m 64M --nographic -smp cores=1,threads=1 -cpu kvm64,+smep
gdb调试:
见下一篇关于babydriver的调试中
添加syscall & 编译ko
首先来做添加syscall
在内核源码下添加一个目录:mysyscall,一个Makefile,一个mysyscall.c
mkdir mysyscall
cd mysyscall
touch mysyscall.c
touch Makefile
编辑Makefile:
obj-y=mysyscall.o
编辑mysyscall.c
#include <linux/kernel.h>
asmlinkage long sys_mysyscall(void){
printk("this is my syscall!\n");
return 0;
}
接着编辑源码根目录下的Makefile,添加mysyscall/
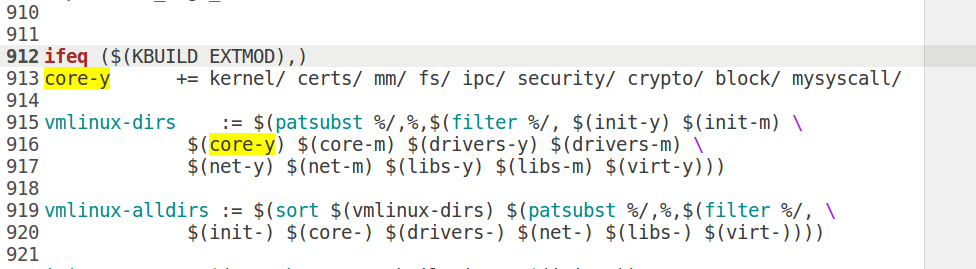
然后编辑include/linux/syscalls.h,末尾添加函数原型
asmlinkage long sys_mysyscall(void);
最后编辑arch/x86/entry/syscalls/syscall_32.tbl和arch/x86/entry/syscalls/syscall_64.tbl,添加系统调用号
//syscall_32.tbl
2333 i386 mysyscall sys_mysyscall
//syscall_64.tbl
2333 common mysyscall sys_mysyscall
至此就添加完syscall,如果调用了2333号,就会输出一句“this is my syscall!\n”
添加了以后同样的,要重新编译一次内核才能生效,make bzImage重新得到 bzImage
现在再来尝试自己编译一个ko文件(编译内核新的模块计算cred的大小)
在kernel源码目录下创建一个新的文件夹和一些文件
mkdir myko
cd myko
touch myko.c
touch Makefile
编辑myko.c
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/cred.h>
MODULE_LICENSE("Dual BSD/GPL");
struct cred c1;
static int myko_init(void)
{
printk("This is my ko!\n");
printk("size of cred : %d \n",sizeof(c1));
return 0;
}
static void myko_exit(void)
{
printk("<1> Bye, cruel world\n");
}
module_init(myko_init);
module_exit(myko_exit);
编辑Makefile,写Makefile的时候注意要使用Tab而不是空格
# at first type on ur terminal that $(uname -r) then u will get the version..
# that is using on ur system
obj-m += myko.o
KDIR =/home/zoe/Desktop/linux-4.4.72/
all:
$(MAKE) -C $(KDIR) SUBDIRS=$(PWD) modules
clean:
rm -rf *.o *.ko *.mod.* *.symvers *.order
然后make命令编译出一个myko.ko文件
将编译好的myko.ko放到busybox的_install目录下
再写个demo测试前面添加的syscall,将demo也放在_install目录下
//demo
//gcc demo.c -static -o demo
#include <unistd.h>
int main(void){
syscall(2333);
return 0;
}
注意,由于我们需要加载自己编译的驱动,myko.ko,因此需要在init文件里面加上一句
insmod /myko.ko
然后再次打包生成 rootfs.img文件
find . | cpio -o --format=newc > ./rootfs.img
接着还是启动boot.sh脚本,可以看到我们的ko和syscal都已经生效了
总算成功了
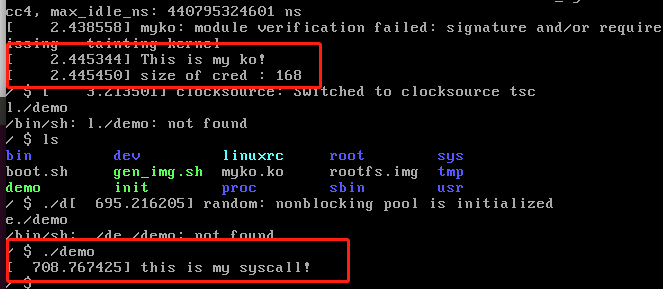
gdb调试看博客里另外一篇入门的babydriver那个题的配置解析
基础知识
内核保护机制
dmesg restrictions : 在dmesg里可以查看到开机信息。若研究内核代码,在代码中插入printk函数,然后通过dmesg观察是一个很好的方法。从Ubuntu 12.04 LTS开始,可以将/proc/sys/kernel/dmesg_restrict设置为1(sudo bash -C "echo 1 > /proc/sys/kernel/dmesg_restrict")将dmesg输出的信息当做敏感信息(默认为0)。
Kernel Address Display Restriction : 在linux内核漏洞利用中常常使用commit_creds和prepare_kernel_cred来完成提权,它们的地址可以从/proc/kallsyms中读取。从Ubuntu 11.04和RHEL 7开始,/proc/sys/kernel/kptr_restrict被默认设置为1以阻止通过这种方式泄露内核地址。
1. KPTI
(Kernel PageTable Isolation,内核页表隔离)
进程地址空间被分成了内核地址空间和用户地址空间,其中内核地址空间映射到了整个物理地址空间,而用户地址空间只能映射到指定的物理地址空间。内核地址空间和用户地址空间共用一个页全局目录表。为了彻底防止用户程序获取内核数据,可以令内核地址空间和用户地址空间使用两组页表集。linux内核从4.15开始支持KPTI,windows上把这个叫KVA Shadow,原理类似。
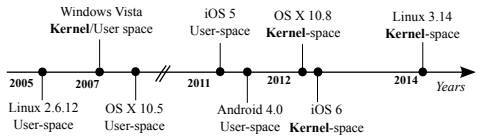
2. KASLR
下面这张图就是几大主流操作系统(windows/linux/ios/os x/android)中ASLR和KASLR的启用情况。不过值得注意的是Android 8.0中为4.4及以后的内核引入了KASLR。
从Ubuntu 14.10开始就支持KASLR了,但并不是默认启用的,需要在内核命令行中加入kaslr开启。
3. SMAP/SMEP
SMAP(Supervisor Mode Access Prevention,管理模式访问保护)
作用:禁止内核访问用户空间的数据
SMEP(Supervisor Mode Execution Prevention,管理模式执行保护)
作用:禁止内核执行用户空间的代码
arm里面叫PXN(Privilege Execute Never)和PAN(Privileged Access Never)。
SMEP类似于前面说的NX,不过一个是在内核态中,一个是在用户态中。
和NX一样SMAP/SMEP需要处理器支持,可以通过cat /proc/cpuinfo查看,在内核命令行中添加nosmap和nosmep禁用。
windows系统从win8开始启用SMEP,windows内核枚举哪些处理器的特性可用,当它看到处理器支持SMEP时通过在CR4寄存器中设置适当的位来表示应该强制执行SMEP,可以通过ROP或者jmp到一个RWX的内核地址绕过。
linux内核从3.0开始支持SMEP,3.7开始支持SMAP。
在没有SMAP/SMEP的情况下把内核指针重定向到用户空间的漏洞利用方式被称为ret2usr。
physmap是内核管理的一块非常大的连续的虚拟内存空间,为了提高效率,该空间地址和RAM地址直接映射。RAM相对physmap要小得多,导致了任何一个RAM地址都可以在physmap中找到其对应的虚拟内存地址。另一方面,我们知道用户空间的虚拟内存也会映射到RAM。这就存在两个虚拟内存地址(一个在physmap地址,一个在用户空间地址)映射到同一个RAM地址的情况。也就是说,我们在用户空间里创建的数据,代码很有可能映射到physmap空间。
基于这个理论在用户空间用mmap()把提权代码映射到内存,然后再在physmap里找到其对应的副本,修改EIP跳到副本执行就可以了。因为physmap本身就是在内核空间里,所以SMAP/SMEP都不会发挥作用。这种漏洞利用方式叫ret2dir。
4. Stack Protector 在编译内核时设置CONFIG_CC_STACKPROTECTOR选项,即可开启该保护
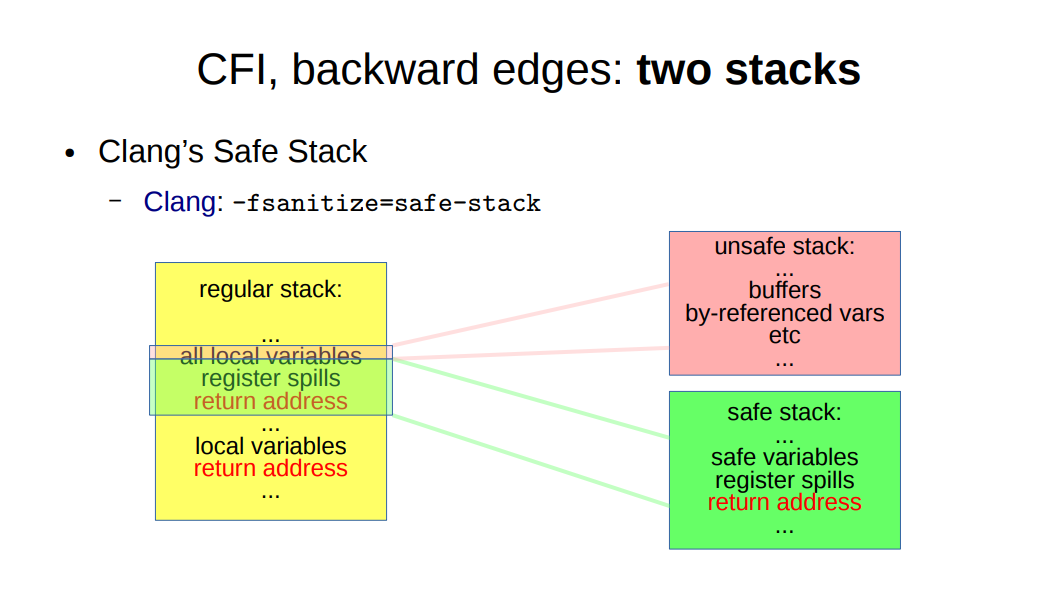
关于函数返回地址的问题属于CFI(Control Flow Integrity,控制流完整性保护)中的后向控制流完整性保护
近几年人们提出了safe-stack和shadow-call-stack引入一个专门存储返回地址的栈替代Stack Protector。可以从下图看到shadow-call-stack开销更小一点。这项技术已经应用于android,而linux内核仍然在等待硬件的支持。
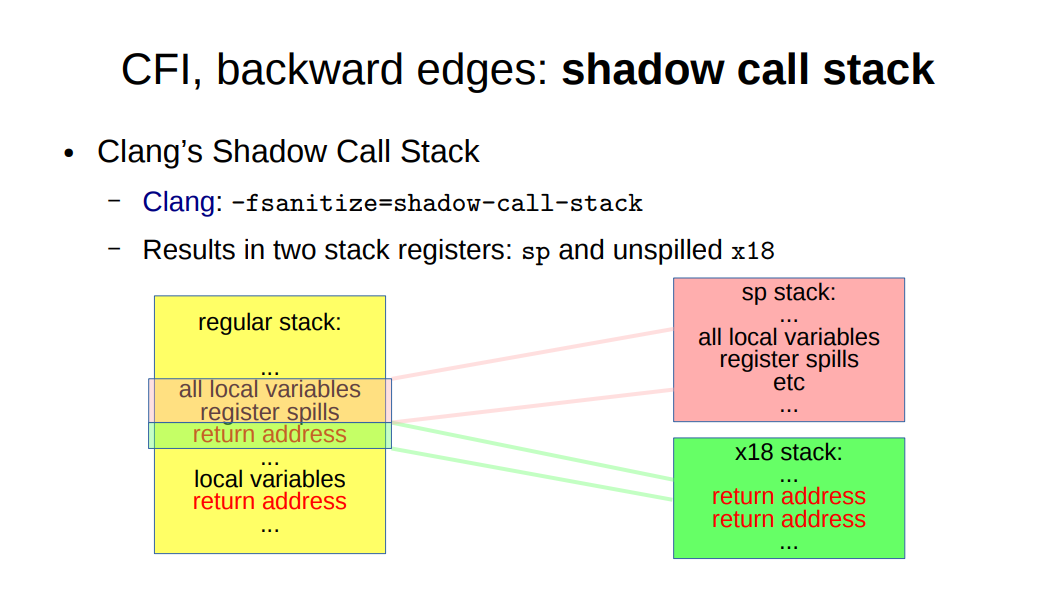
5. address protection
由于内核空间和用户空间共享虚拟内存地址,因此需要防止用户空间mmap的内存从0开始,从而缓解NULL解引用攻击。windows系统从win8开始禁止在零页分配内存。从linux内核2.6.22开始可以使用sysctl设置mmap_min_addr来实现这一保护。从Ubuntu 9.04开始,mmap_min_addr设置被内置到内核中(x86为64k,ARM为32k)。
Cred结构体
什么是cred结构体
是kernel中用来记录进程权限的,这个结构体中保存了该进程的权限等信息如(uid,gid)等,如果能修改这个结构体那么就修改了这个进程的权限。
/*
* The security context of a task
*
* The parts of the context break down into two categories:
*
* (1) The objective context of a task. These parts are used when some other
* task is attempting to affect this one.
*
* (2) The subjective context. These details are used when the task is acting
* upon another object, be that a file, a task, a key or whatever.
*
* Note that some members of this structure belong to both categories - the
* LSM security pointer for instance.
*
* A task has two security pointers. task->real_cred points to the objective
* context that defines that task's actual details. The objective part of this
* context is used whenever that task is acted upon.
*
* task->cred points to the subjective context that defines the details of how
* that task is going to act upon another object. This may be overridden
* temporarily to point to another security context, but normally points to the
* same context as task->real_cred.
*/
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key __rcu *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
struct rcu_head rcu; /* RCU deletion hook */
};
一般来说,改到suid的时候基本上可以认为是root了,也就是填充28个0即可
关于一些文件:
- bzImage是vmlinuz经过gzip压缩后的文件,适用于大内核
- vmlinux是未压缩的内核
- vmlinuz是vmlinux的压缩文件。
- vmlinux 是ELF文件,即编译出来的最原始的文件。
- vmlinuz应该是由ELF文件vmlinux经过OBJCOPY后,并经过压缩后的文件
- zImage是vmlinuz经过gzip压缩后的文件,适用于小内核
Ring Model
intel CPU 将 CPU 的特权级别分为 4 个级别:Ring 0, Ring 1, Ring 2, Ring 3。
Ring0 只给 OS 使用,Ring 3 所有程序都可以使用,内层 Ring 可以随便使用外层 Ring 的资源。
使用 Ring Model 是为了提升系统安全性,例如某个间谍软件作为一个在 Ring 3 运行的用户程序,在不通知用户的时候打开摄像头会被阻止,因为访问硬件需要使用 being 驱动程序保留的 Ring 1 的方法。
大多数的现代操作系统只使用了 Ring 0 和 Ring 3。
Loadable Kernel Modules(LKMs)
可加载核心模块 (或直接称为内核模块) 就像运行在内核空间的可执行程序,包括:
-
驱动程序(Device drivers)
- 设备驱动
- 文件系统驱动
- …
内核扩展模块 (modules)
LKMs 的文件格式和用户态的可执行程序相同,Linux 下为 ELF,Windows 下为 exe/dll,mac 下为 MACH-O,因此我们可以用 IDA 等工具来分析内核模块。
模块可以被单独编译,但不能单独运行。它在运行时被链接到内核作为内核的一部分在内核空间运行,这与运行在用户控件的进程不同。
模块通常用来实现一种文件系统、一个驱动程序或者其他内核上层的功能。
Linux 内核之所以提供模块机制,是因为它本身是一个单内核 (monolithic kernel)。单内核的优点是效率高,因为所有的内容都集合在一起,但缺点是可扩展性和可维护性相对较差,模块机制就是为了弥补这一缺陷。
syscall
系统调用,指的是用户空间的程序向操作系统内核请求需要更高权限的服务,比如 IO 操作或者进程间通信。系统调用提供用户程序与操作系统间的接口,部分库函数(如 scanf,puts 等 IO 相关的函数实际上是对系统调用的封装 (read 和 write))
在 /usr/include/x86_64-linux-gnu/asm/unistd_64.h 和 /usr/include/x86_64-linux-gnu/asm/unistd_32.h 分别可以查看 64 位和 32 位的系统调用号。
kptr_restrict/dmesg_restrict
内核提供控制变量 /proc/sys/kernel/kptr_restrict 来进行修改. 从内核文档 Documentation/sysctl/kernel.txt中可以看到 kptr_restrict 用于控制内核的一些输出打印.
kptr_restrict 权限描述 2 内核将符号地址打印为全0, root和普通用户都没有权限 1 root用户有权限读取, 普通用户没有权限 0 root和普通用户都可以读取
| kptr_restrict | 权限描述 |
|---|---|
| 2 | 内核将符号地址打印为全0, root和普通用户都没有权限 |
| 1 | root用户有权限读取, 普通用户没有权限 |
| 0 | root和普通用户都可以读取 |
同样的 ,设置dmesg_restrict为1, 是用来禁止普通用户查看demsg信息
- 0:不限制
- 1:只有特权用户能够查看
内核态函数
相比用户态库函数,内核态的函数有了一些变化
- printf() -> printk(),但需要注意的是 printk() 不一定会把内容显示到终端上,但一定在内核缓冲区里,可以通过 dmesg 查看效果
- memcpy() -> copy_from_user()/copy_to_user()
- copy_from_user() 实现了将用户空间的数据传送到内核空间
- copy_to_user() 实现了将内核空间的数据传送到用户空间
- malloc() -> kmalloc(),内核态的内存分配函数,和 malloc() 相似,但使用的是 slab/slub 分配器
- free() -> kfree(),同 kmalloc()
另外要注意的是,kernel 管理进程,因此 kernel 也记录了进程的权限。kernel 中有两个可以方便的改变权限的函数:
- int commit_creds(struct cred *new)
- struct cred prepare_kernel_cred(struct task_struct daemon)
从函数名也可以看出,执行 commit_creds(prepare_kernel_cred(0)) 即可获得 root 权限(root 的 uid,gid 均为 0)
执行 commit_creds(prepare_kernel_cred(0)) 也是最常用的提权手段,两个函数的地址都可以在 /proc/kallsyms 中查看(较老的内核版本中是 /proc/ksyms)
可以通过以下方法在qemu中看到地址
/ $ grep commit_creds /proc/kallsyms
ffffffff810a1420 T commit_creds
ffffffff81d88f60 R __ksymtab_commit_creds
ffffffff81da84d0 r __kcrctab_commit_creds
ffffffff81db948c r __kstrtab_commit_creds
ioctl
直接查看 man 手册
NAME
ioctl - control device
SYNOPSIS
#include <sys/ioctl.h>
int ioctl(int fd, unsigned long request, ...);
DESCRIPTION
The ioctl() system call manipulates the underlying device parameters of special
files. In particular, many operating characteristics of character special
files (e.g., terminals) may be controlled with ioctl() requests. The argument
fd must be an open file descriptor.
The second argument is a device-dependent request code. The third argument is
an untyped pointer to memory. It's traditionally char *argp (from the days
before void * was valid C), and will be so named for this discussion.
An ioctl() request has encoded in it whether the argument is an in parameter or
out parameter, and the size of the argument argp in bytes. Macros and defines
used in specifying an ioctl() request are located in the file <sys/ioctl.h>.
可以看出 ioctl 也是一个系统调用,用于与设备通信。 int ioctl(int fd, unsigned long request, …) 的第一个参数为打开设备 (open) 返回的 文件描述符,第二个参数为用户程序对设备的控制命令,再后边的参数则是一些补充参数,与设备有关。
使用 ioctl 进行通信的原因:
操作系统提供了内核访问标准外部设备的系统调用,因为大多数硬件设备只能够在内核空间内直接寻址, 但是当访问非标准硬件设备这些系统调用显得不合适, 有时候用户模式可能需要直接访问设备。
比如,一个系统管理员可能要修改网卡的配置。现代操作系统提供了各种各样设备的支持,有一些设备可能没有被内核设计者考虑到,如此一来提供一个这样的系统调用来使用设备就变得不可能了。
为了解决这个问题,内核被设计成可扩展的,可以加入一个称为设备驱动的模块,驱动的代码允许在内核空间运行而且可以对设备直接寻址。一个 Ioctl 接口是一个独立的系统调用,通过它用户空间可以跟设备驱动沟通。对设备驱动的请求是一个以设备和请求号码为参数的 Ioctl 调用,如此内核就允许用户空间访问设备驱动进而访问设备而不需要了解具体的设备细节,同时也不需要一大堆针对不同设备的系统调用
状态切换
user space to kernel space
当发生 系统调用,产生异常,外设产生中断等事件时,会发生用户态到内核态的切换,具体的过程为:
- 通过 swapgs 切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换,目的是保存 GS 值,同时将该位置的值作为内核执行时的 GS 值使用
- 将当前栈顶(用户空间栈顶)记录在 CPU 独占变量区域里,将 CPU 独占区域里记录的内核栈顶放入 rsp/esp。
- 通过 push 保存各寄存器值,具体的 代码 如下:
ENTRY(entry_SYSCALL_64)
/* SWAPGS_UNSAFE_STACK是一个宏,x86直接定义为swapgs指令 */
SWAPGS_UNSAFE_STACK
/* 保存栈值,并设置内核栈 */
movq %rsp, PER_CPU_VAR(rsp_scratch)
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
/* 通过push保存寄存器值,形成一个pt_regs结构 */
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
pushq %rax /* pt_regs->orig_ax */
pushq %rdi /* pt_regs->di */
pushq %rsi /* pt_regs->si */
pushq %rdx /* pt_regs->dx */
pushq %rcx tuichu /* pt_regs->cx */
pushq $-ENOSYS /* pt_regs->ax */
pushq %r8 /* pt_regs->r8 */
pushq %r9 /* pt_regs->r9 */
pushq %r10 /* pt_regs->r10 */
pushq %r11 /* pt_regs->r11 */
sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */
-
通过汇编指令判断是否为 x32_abi。
-
通过系统调用号,跳到全局变量 sys_call_table 相应位置继续执行系统调用。
kernel space to user space
退出时,流程如下:
- 通过 swapgs 恢复 GS 值
- 通过 sysretq 或者 iretq 恢复到用户控件继续执行。如果使用 iretq 还需要给出用户空间的一些信息(CS, eflags/rflags, esp/rsp 等)
slab/slub分配器
这是一个比较大的内容,内核中也需要使用到内存的分配,类似于用户空间malloc的功能。在内核中没有libc,所以没有malloc,但是需要这样的功能,所以有kmalloc,其实现是使用的slab/slub分配器,现在多见的是slub分配器。这个分配器通过一个多级的结构进行管理。首先有cache层,cache是一个结构,里边通过保存空对象,部分使用的对象和完全使用了对象来管理,对象就是指内存对象,也就是用来分配或者已经分配的一部分内核空间。
kmalloc使用了多个cache,一个cache对应一个2的幂大小的一组内存对象。
slab分配器严格按照cache去区分,不同cache的无法分配在一页内,slub分配器则较为宽松,不同cache如果分配相同大小,可能会在一页内,这个点很重要,之后的exp会用到。
相关指令
- insmod: 将指定模块加载到内核中
- rmmod: 从内核中卸载指定模块
- lsmod: 列出已经加载的模块
其他参考资料
linux内核源码 在线:https://elixir.bootlin.com/linux/latest/source
https://mirrors.edge.kernel.org/pub/linux/kernel/
PPT https://github.com/bash-c/slides/blob/master/pwn_kernel/13_lecture.pdf
kernel map
http://www.makelinux.net/kernel_map/




